基于GNIPSO-SVR的水質(zhì)預測模型研究(六)
發(fā)布時間:2021-06-19 23:26
編輯者:特邀作者余秀梅
為了更好的驗證模型的預測效果,本文采用均方根誤差(RMSE)��、平均絕對值百分比誤差(MAPE)、平均絕對誤差(MAE)的三個評價指標�����。
如式(24)-(26):
均方根誤差(RMSE):
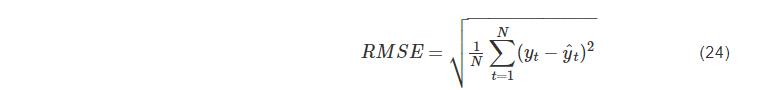
平均絕對值百分比誤差(MAPE):
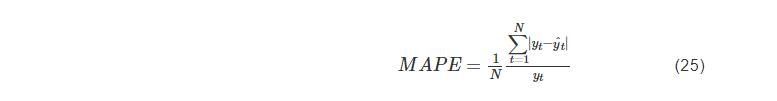
平均絕對誤差(MAE):

式(24)-(26)中���,yt為第t天的溶解氧含量;yˆt為第t天的溶解氧含量的預測值���;N為預測樣本數(shù)�����。均方根誤差是常見得衡量回歸模型性能的評價指標��,RMSE指標越小����,說明模型的預測精度越高�。
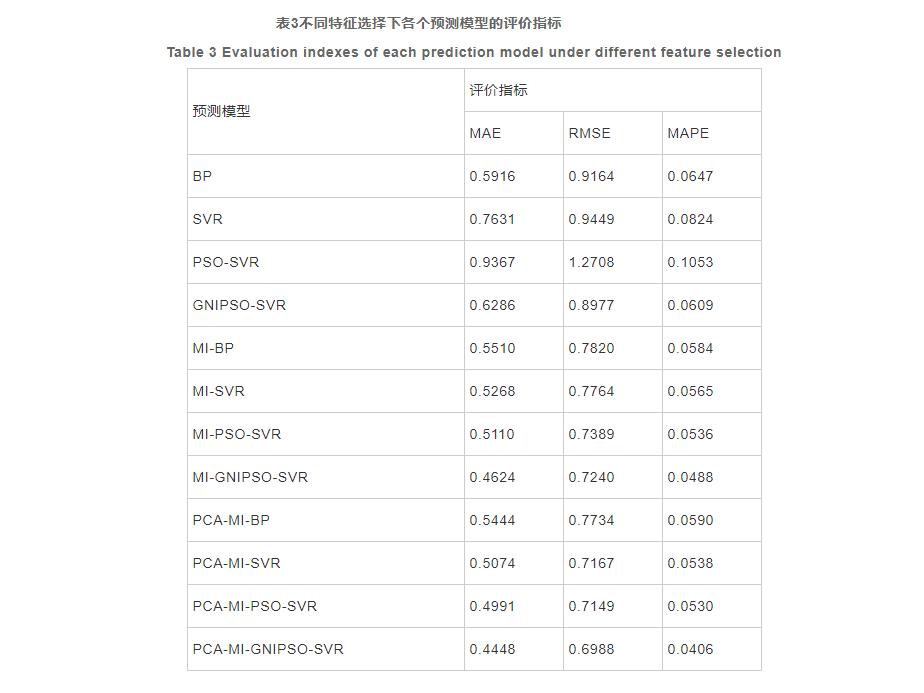
本文將BP神經(jīng)網(wǎng)絡(luò)模型、SVR��、PSO-SVR�、GNIPSO-SVR模型分別在未特征選擇�����、MI特征選擇和PCA-MI組合特征選擇的方法下進行仿真實驗并對預測結(jié)果進行了統(tǒng)計分析����,如表3所示����。從表3可以看出,采用PCA-MI特征選擇方法的預測模型性能均優(yōu)于未特征選擇和MI特征選擇的預測模型����,而且對于未特征選擇的溶解氧數(shù)據(jù)集,BP神經(jīng)網(wǎng)絡(luò)的預測性能高于SVR模型�,經(jīng)過MI和PCA-MI特征選擇方法的SVR模型的預測性能明顯優(yōu)于BP神經(jīng)網(wǎng)絡(luò)模型,再次說明SVR預測模型適用于小樣本數(shù)據(jù)集��。采用MI特征選擇方法時�����,選取互信息值較大的作為溶解氧的特征變量�����,在確定選取的數(shù)目時具有一定的主觀性,而且也忽略了選取的特征變量間的相關(guān)性�,降低溶解氧預測模型的精度。
綜上所述���,在研究水質(zhì)指標溶解氧問題時選擇的特征變量過少導致建模效果不佳�����,預測結(jié)果不具有代表性��,特征變量多可以提供描述問題的更多信息,但數(shù)據(jù)中會存在無關(guān)和弱相關(guān)且冗余的特征變量�����,會降低模型的泛化性能���。在對溶解氧預測實踐中�,PCA-MI特征選擇方法選取的特征變量更具有代表性�����,能更有效的提高模型預測性能����。
從表3的BP���、SVR、PSO-SVR和GNIPSO-SVR模型之間的評價指標比較發(fā)現(xiàn)��,在未特征選擇�����、MI特征選擇和PCA-MI組合特征選擇上���,GNIPSO-SVR模型的MAE���、MSE和RMSE均較低,而且經(jīng)過PCA-MI組合特征選擇的GNIPSO-SVR模型的評價指標最低��,說明了GNIPSO-SVR模型具有較高的預測性能�����。
聲明:本文所用圖片�、文字來源《信息與控制》,版權(quán)歸原作者所有。如涉及作品內(nèi)容���、版權(quán)等問題��,請與本網(wǎng)聯(lián)系刪除���。
相關(guān)鏈接:溶解氧,評價����,樣本



















登錄后才可以評論